머신러닝에서 분류(Classification) 문제를 해결하기 위한 알고리즘은 매우 다양하게 존재합니다. 그중에서 K-최근접 이웃(K-Nearest Neighbors, KNN)과 나이브 베이즈(Naive Bayes)는 기본 개념이 간단하면서도 실제 응용에서 좋은 성능을 보이는 대표적인 지도학습 알고리즘으로 꼽을 수 있습니다. 두 모델 모두 분류에 효과적이지만 작동 방식, 전제 조건, 성능 측면에서 큰 차이가 있습니다. 이번에는 두 알고리즘의 특징을 실제 코드 예제와 함께 비교하고, 어떤 상황에서 더 효과적인지를 한 번 살펴보도록 하겠습니다.
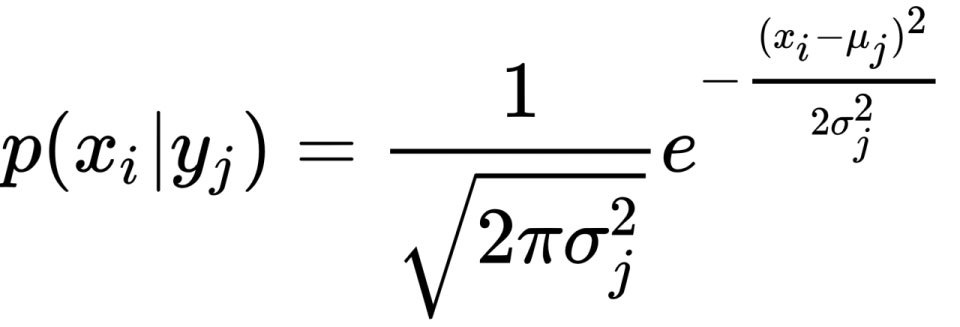
1. K-최근접 이웃(KNN) 알고리즘의 이해와 구현
KNN은 가장 직관적인 분류 알고리즘 중 하나로, 학습 과정이 거의 없고 예측 시점에서 거리 기반 계산을 통해 분류를 수행합니다. 즉, 훈련 데이터를 저장해 두었다가 새로운 데이터가 들어오면 가장 가까운 K개의 이웃을 찾아 다수결로 클래스를 예측합니다. 이때 사용하는 거리 측정 방식으로는 유클리디안 거리(Euclidean Distance)가 가장 일반적인 예시입니다.
KNN은 간단하고 이해하기 쉬우며, 하이퍼파라미터인 K 값을 조절함으로써 모델의 민감도를 제어할 수 있습니다. 하지만 데이터가 많아질수록 계산량이 급격히 증가하고, 고차원 데이터에서는 성능이 저하될 수 있는 단점도 존재하곤 합니다.
아래의 예제로 함께 살펴보겠습니다. scikit-learn을 이용하여 붓꽃(iris) 데이터셋에 대해 KNN 분류기를 적용하는 코드입니다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 불러오기
iris = load_iris()
X = iris.data
y = iris.target
# 훈련/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# KNN 모델 정의 및 학습
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 예측 및 정확도 평가
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"KNN 정확도: {accuracy:.2f}")
KNN에서는 K 값을 변화시키면서 최적의 값을 찾는 것이 중요합니다. K 값이 너무 작으면 과적합(overfitting)이 발생하고, 너무 크면 과소적합(underfitting)이 될 수 있습니다. 일반적으로 홀수 값을 사용하며 교차 검증을 통해 적절한 값을 결정하는 것이 좋습니다.
2. 나이브 베이즈(Naive Bayes) 알고리즘의 원리와 구현
나이브 베이즈는 확률 기반 분류 알고리즘으로, 베이즈 정리를 기반으로 하며 각 특징(feature)이 독립적이라는 전제를 가정합니다. 이 '독립성' 가정 때문에 '나이브(naive)'라는 이름이 붙었습니다. 간단한 계산으로 빠르게 분류할 수 있으며, 텍스트 분류와 같이 고차원 sparse 데이터에 특히 효과적입니다.
베이즈 정리는 다음과 같은 식으로 표현됩니다:
P(Y|X) = (P(X|Y) * P(Y)) / P(X)여기서 Y는 클래스, X는 입력 데이터입니다. 나이브 베이즈는 이 식을 기반으로 각 클래스의 사후 확률을 계산하고, 가장 높은 확률을 가진 클래스로 예측합니다. 다양한 변형(가우시안, 멀티노미얼, 베르누이)이 존재하며, 데이터의 성격에 따라 적절한 모델을 선택할 수 있습니다.
아래의 예제로 함께 살펴보겠습니다. 멀티노미얼 나이브 베이즈를 사용하여 사이킷런의 뉴스 데이터셋을 분류하는 예제입니다.
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 뉴스 데이터 로드
newsgroups = fetch_20newsgroups(subset='all', categories=['sci.space', 'rec.sport.baseball'])
X = newsgroups.data
y = newsgroups.target
# 텍스트 벡터화
vectorizer = CountVectorizer()
X_vectorized = vectorizer.fit_transform(X)
# 훈련/테스트 분리
X_train, X_test, y_train, y_test = train_test_split(X_vectorized, y, test_size=0.2, random_state=42)
# 나이브 베이즈 모델 훈련
model = MultinomialNB()
model.fit(X_train, y_train)
# 예측 및 정확도 출력
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Naive Bayes 정확도: {accuracy:.2f}")
이 알고리즘은 계산량이 적고 속도가 빠르며, 특히 텍스트 데이터에서 강력한 성능을 발휘합니다. 하지만 특성 간 독립성 가정을 만족하지 않을 경우 정확도가 낮아질 수 있습니다. 따라서 특징 간 상관관계가 적은 경우에 주로 활용됩니다.
3. KNN vs Naive Bayes: 성능 비교 및 최적화 전략
KNN과 나이브 베이즈는 각각의 강점이 뚜렷한 알고리즘입니다. KNN은 데이터 분포가 명확하고, 거리 기반 유사성이 중요한 경우에 유리합니다. 반면 나이브 베이즈는 고차원 데이터셋, 특히 단어 빈도와 같은 특성이 있는 텍스트 데이터에 적합합니다.
KNN은 학습 과정이 없기 때문에 저장된 데이터가 클수록 예측 시간이 오래 걸릴 수 있습니다. 이에 비해 나이브 베이즈는 학습 시점에 통계치를 미리 계산하기 때문에 예측이 빠릅니다. 다만 나이브 베이즈는 입력 특성의 분포나 독립성 여부에 따라 성능이 크게 달라질 수 있습니다.
성능 최적화를 위해 KNN은 K 값 조정, 거리 측정 방식 변경(예: 맨해튼 거리), 차원 축소 기법 적용(PCA 등)을 사용할 수 있습니다. 나이브 베이즈는 텍스트 전처리, n-그램 적용, TF-IDF 가중치 조정 등을 통해 성능을 높일 수 있습니다.
결론적으로, 두 모델 모두 상황에 맞게 선택하고 하이퍼파라미터 튜닝을 통해 최적화하면 실무에 적용 가능한 충분한 정확도를 확보할 수 있습니다. 실제 프로젝트에서는 교차 검증을 통해 각각의 모델 성능을 실험하고, 데이터 특성에 가장 잘 맞는 알고리즘을 선택하는 것이 중요할 것 같습니다.